
Optimiser son site avec le terminal Linux
Grâce au terminal Linux, il est possible de se passer de certains outils SEO pour optimiser son site. Vous pouvez vérifier les erreurs 404, récupérer une information précise ou encore traiter les fichiers logs. Toutefois, si vous devez installer deux programmes, je vous conseillerai Lynx et Linkchecker.
Lynx
Présentation
Lynx est un navigateur en mode texte. Il s’utilise directement dans votre terminal Linux. Pour naviguer au sein d’un site, il vous faudra utiliser le clavier. Grâce à Lynx, vous pouvez voir votre site comme le voient les bots des moteurs de recherche. Vous pourrez facilement voir les éléments bloquants sur une page et, surtout, vérifier si votre contenu est bien lu par les bots.
Un site full flash donne ça :
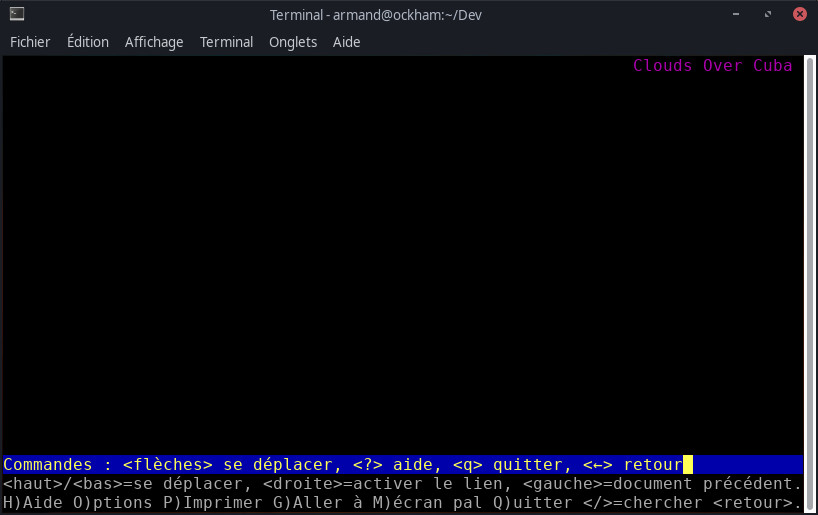
Au mieux, vous aurez ça :
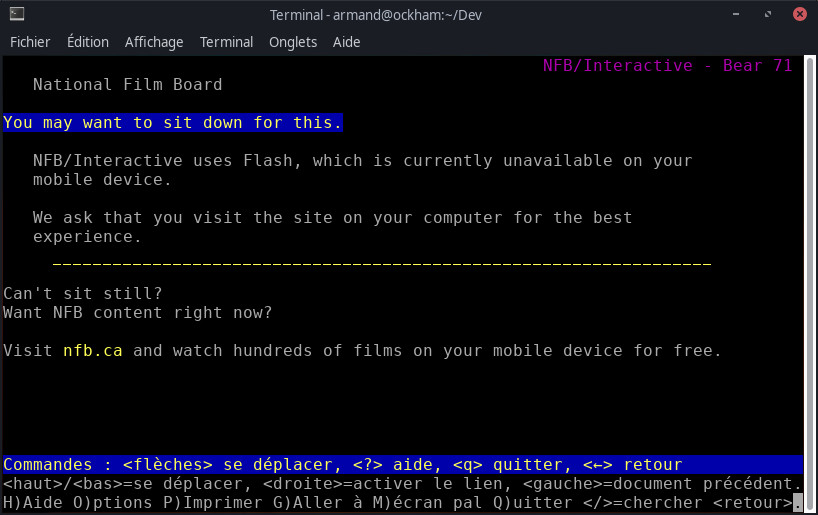
Alors qu’un site construit correctement sera navigable dans votre terminal. Par exemple :
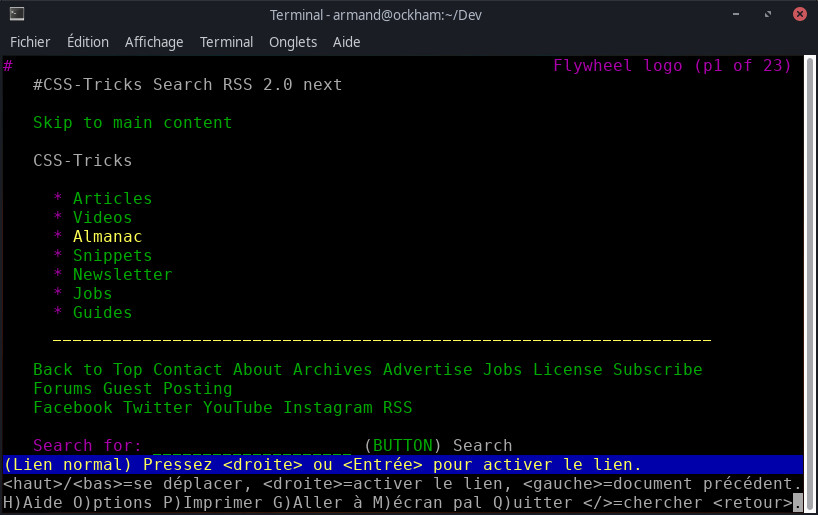
Les commandes Lynx utiles pour votre référencement
Grâce aux options disponibles, vous pouvez utiliser Lynx pour récupérer certaines informations.
Par exemple, pour récuperer le Header status il suffit de saisir la commande :
lynx -dump -head https://www.example.com/L’option -dump permet de rediriger le fichier vers la sortie standard, c’est-à-dire l’écran. L’option -head retourne le « Header status » de la page indiquée. À noter, vous pouvez faire la même chose sans Lynx :
curl -I https://www.example.com/Dans cet exemple, l’option -I indique à curl de récupérer le « Header status ».
Pour cibler certaines informations, Lynx à lui seul ne suffira pas. Il vous faudra le coupler avec d’autres commandes Linux : grep, wc ou encore awk.
- Compter le nombre de liens sur une page :
lynx -dump -listonly -nonumbers https://www.example.com | wc -l- Compter uniquement le nombre de liens externes sur une page :
lynx -dump -listonly -nonumbers https://www.example.com | grep -v "https://www.example.com/" | wc -l- Vérifier dans le coude source si Matomo est installé :
lynx -source www.example.com | grep -q '_paq.push' && echo "Matomo installé" || echo "Matomo non installé"- Récupérer le contenu de l’élément
titled’une page :
lynx -source https://www.example.com/ | awk 'BEGIN{IGNORECASE=1;FS="<title>|</title>";RS=EOF} {print $2}'En vrac, les options présentées ici :
-listonly: permet d’indiquer à Lynx de présenter les résultats sous forme de liste-nonumbers: permet de retirer la numérotation devant les liens et l’en-tête (vous pouvez voir la différence en inscrivant la sortie dans un fichier)-sourceindique à Lynx de regarder dans le code source de la page-qindique àgrepde ne pas afficher la sortie de la commande à l’écran
Pour awk, les commandes sont généralement un peu plus complexes :
BEGINpermet d’indiquer le début des instructionsIGNORECASE=1indique àawkde ne pas se préoccuper des majuscules/minisculesFSpermet d’indiquer le séparateurRSpermet d’indiquer le séparateur d’enregistrement ; ici,EOFsignifie la fin du fichierprint $xoù x représente un nombre indique quelle colonne afficher
Quelques commandes Linux utiles pour votre SEO
Des commandes simples
Votre terminal peut être un précieux allié si vous souhaitez analyser les logs de votre serveur. Grâce à lui vous pourrez par exemple :
- Vérifier les dates de passage d’un bot
grep -h -i -e 'googlebot' -e 'bingbot' access.log >> bots.txt- Compter le nombre de passage d’un bot
grep -e 'Googlebot' access.log | wc -l- Compter le nombre de passage d’un bot par mois
grep -h -i -e 'Googlebot' access.log | awk '{print $5}' | awk -F/ '{print $2}' | sort -M | uniq -c- Récupérer toutes les erreurs 404 du fichier log
awk '$12 == "404"' access.log > 404.csvQuelques précisions sur les options présentées ici :
-hsupprime le préfixe de nom de fichier en sortie-iindique àgrepde ne pas se préoccuper des majuscules/miniscules-epermet de préciser la chaîne de caractères à rechercher, cela peut-être une expression régulière- Pour
awk, la chaîne$12précise qu’il faut rechercher « 404 » dans la 12e colonne (les colonnes sont séparées par un espace) ; cela peut varier chez vous.
Des commandes plus complexes
Pour générer la liste de toutes les URLs d’un site :
wget --spider --no-check-certificate --force-html -nd --delete-after -r -l 0 https://www.example.com 2>&1 | grep '^--' | awk '{ print $3 }' | grep -v '\.\(css\|js\|png\|gif\|jpg\|svg\)$' | sort | uniq > url-list.txtLa commande est déjà plus complexe ; elle fait intervenir wget, grep, awk, sort et uniq.
Que fait-elle exactement ?
wget:--spiderpermet d’indiquer qu’on ne souhaite rien télécharger--no-check-certificate: ne pas vérifier le certificat du serveur, cette information ne nous intéresse pas--force-htmlpour traiter les fichiers d’entrée comme du HTML-nd: ne pas créer de répertoire--delete-afterpermet de détruire les fichiers locaux après l’exécution de la commande (on ne veut que la liste d’URLs, rien d’autre)-rpermet de lancer la commande récursivement-l 0indique le niveau de récursion maximal ; ici « 0 » indique à l’infini2>&1: on redirige l’erreur standard (stderr) vers la sortie standard (stdout) ; cela permet de conserver les erreurs
grep:- sa première occurrence permet de filtrer la sortie de
wgetpour récupérer seulement les informations commençant par-- - l’option
-vdans la deuxième occurrence permet de sélectionner toutes les lignes qui ne correspondent pas à l’expression régulière qui suit (on filtre les fichiers images, css et js)
- sa première occurrence permet de filtrer la sortie de
awk: on lui indique de récupérer la 3e colonnesortetuniqpermettent de supprimer les URLs en double
Linkchecker
Linkchecker est un autre outil très pratique. Il vous permet de vérifier si votre site contient des erreurs 404 par exemple.
- Ne lister que les erreurs internes :
linkchecker -o csv www.example.com > erreurs.csv- Lister tous les liens d’un site avec les
Header status:
linkchecker -v --check-extern https://www.example.com/ -o csv > touslesliens.csvQuelques explications pour ces commandes :
- l’option
-oprécise le format de sortie ; ici, j’ai choisi CSV - l’option
-vindique à linkchecker d’être verbeux, c’est-à-dire d’afficher toutes les informations --check-externpermet d’indiquer à linkchecker de vérifier les liens pointant vers des domaines externes- l’opérateur
>indique permet d’afficher le résultat dans un fichier plutôt qu’à l’écran
Appropriez-vous ces commandes Linux
Au final, ces commandes ne seront peut-être pas suffisantes pour vos besoins. Elles vous donnent des pistes pour vos propres besoins. En les combinant, vous pouvez arriver à faire un rapport assez complet de l’état de votre site et des améliorations à apporter. Si vous voulez les maîtriser, je vous conseille de regarder en premier lieu la documentation grâce à lacommande --help. Cependant, ce ne sera pas toujours suffisant. Par exemple, les différentes options de awk ne sont pas présentées ; complétez vos recherches avec votre moteur de recherche préféré.
Si vous ne voyez toujours pas ce que peut vous apporter ces commandes, imaginez-les dans un script bash. Vous pouvez, par exemple, générer la liste des URLs d’un site et, pour cette liste, associer le contenu de l’élément title. Et pourquoi pas la meta description ? Grâce à ces commandes, vous pouvez éviter certains outils parfois payants, parfois remplis de pubs.
0 commentaire
Laisser un commentaire